Ayer por la tarde, hacia la hora de comer, la cuenta de Twitter del Partido Popular reflejaba la siguiente cita:
. @c_floriano : "No podemos tolerar que se ponga en duda que en el PP no ha habido prácticas irregulares en el manejo del dinero".
— Partido Popular (@PPopular) February 4, 2013
Confieso que a mí me la pasaron, la leí y no vi nada raro. Así que me sorprendió la ristra de respuestas que en poco tiempo acumulaba señalando la falta de pericia del autor: mucha gente sostenía que el PP acababa de admitir, con ese comentario, que se han cometido irregularidades (no caerá esa breva…). Lo primero que pensé, por tanto, es que yo había cometido algún error al leer rápido, que tal vez esa acumulación de negaciones (tres, en concreto: el primer «no», la propia «duda» y el segundo «no») escondiese un significado no deseado —porque el deseado lo da el contexto que todos conocemos—. Y tras un análisis pormenorizado (varios en realidad, por si acaso), concluí que mi primera impresión era acertada: está perfectamente escrito y dice lo que quiere decir. Así lo expresé en Twitter, no falto de énfasis:
Parece ser que la gente se está retratando a raíz de este tweet https://t.co/HwQ0195m ESTÁ BIEN ESCRITO, COÑO
— Iñaki Úcar (@Enchufa2) February 4, 2013
Además del despiporre generalizado, no faltó la gente que aprovechó para insultar directamente (que no digo que no se lo merezcan, pero cuidado con escupir hacia el cielo, que ya se sabe…):
@c0rvid0 No es que dude, es que está claro que está bien. Y la gente descalificando gratuitamente y haciendo un RIDÍCULO que no admitirá
— Iñaki Úcar (@Enchufa2) February 4, 2013
Muchos han atribuido el supuesto error al esquema de doble negación típico del castellano. Pues bien: no existe tal doble negación. Podemos consultar en la RAE cuándo se da esta construcción, como en el uso de adverbios que expresan negación («nadie», «tampoco», etc.) cuando van pospuestos al verbo. Este caso no tiene nada que ver. Yo atribuyo la confusión a la acumulación de negaciones en forma de subordinación y a las ganas que les tiene la gente.
Como el mío, fueron apareciendo mensajes, poco a poco, que avisaban de la corrección de la cita. Entre las discusiones ajenas que he ojeado y las propias, he visto desde gente que afirma que es incorrecta hasta quien afirma que es correcta gramaticalmente pero resulta ambigua, luego incorrecta; también la evolución de una postura a otra. Por ello, quiero exponer aquí algunos procedimientos que he empleado yo para analizar dicha cita y llegar a la conclusión de que es correcta y no hay posible ambigüedad.
[Nota: mientras escribo estas líneas, veo que @chusop ya ha publicado una explicación sobre la que tengo poco que añadir, la verdad].
La primera aproximación es la obvia: empezar de atrás hacia adelante, dado que tenemos una cadena de subordinadas.
- El PP sostiene que no ha habido prácticas irregulares.
- La gente duda de lo anterior.
- El PP no tolera esa duda.
Aprovecho para hacer notar que no hay otra forma de entender las subordinadas ni queriendo y con esfuerzo: está claro que «dudar que» va dentro de «tolerar que». Segunda aproximación: si las negaciones nos molestan, expresemos las mismas proposiciones de forma afirmativa (y si nos salen otras negaciones, les damos la vuelta también; la negación sobre «tolerar» la dejo porque resulta trivial).
- El PP sostiene que no ha habido prácticas irregulares, ergo el PP afirma su integridad.
- La gente duda de la integridad del PP, ergo la gente cree en la falta de integridad del PP, ergo la gente cree que son unos mangantes.
- El PP no tolera que se dude de su integridad, ergo el PP no tolera que la gente crea que no tienen integridad, ergo el PP no tolera que la gente crea que son unos mangantes.
Cristalino. Ante la claridad de este último paso, puedo admitir que la acumulación de negaciones enmaraña el significado, pero en ningún caso se comete incorrección o ambigüedad. De hecho, ¿hasta qué punto da lugar a confusión? Estoy convencido de que si se hubiese tratado de otro tema y otro autor, nadie le habría buscado la vuelta (o «no le habría buscado la vuelta nadie», esta vez sí, con doble negación): se habría entendido perfectamente y a la primera —aunque esto nunca lo sabremos—.
Llegados a este punto, he de confesar que todo lo anterior no es más que una excusa para lo que viene ahora. En mi discusión particular de ayer tarde, un twittero me dijo lo siguiente:
@Enchufa2 @chusop @c0rvid0 No sé si te has dado cuenta, pero lengua y matemáticas no son la misma asignatura. No es ciencia, precisamente.
— Carlos Morales (@cmoralesweb) February 4, 2013
A lo que yo contesté: CHALLENGE ACCEPTED. ¿De qué nos serviría el lenguaje si no fuese formalmente lógico? Por supuesto que hay matemáticas ahí detrás: podemos analizar la cita mediante lógica de predicados [¡peligro, matemáticas!]. Empezamos.
Sean los siguientes predicados:

Nuestra cita queda formalizada en la siguiente expresión: 
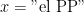
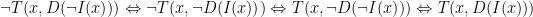
Esto quiere decir que deberían ser equivalentes las siguientes proposiciones:
- [Original] El PP no tolera que se ponga en duda que el PP no tiene irregularidades.
- El PP no tolera que no se ponga en duda que el PP tiene irregularidades.
- El PP tolera que no se ponga en duda que el PP no tiene irregularidades.
- El PP tolera que se ponga en duda que el PP tiene irregularidades.
Queda como ejercicio para el lector comprobar que, efectivamente, es así. De la misma forma, la negación de la proposición generará otras tres equivalentes (o, lo que es lo mismo, aplicamos a la original un número impar de negaciones):
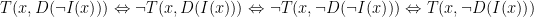
Esto quiere decir que deberían ser equivalentes las siguientes proposiciones:
- [Original negada] El PP tolera que se ponga en duda que el PP no tiene irregularidades.
- El PP no tolera que se ponga en duda que el PP tiene irregularidades.
- El PP no tolera que no se ponga en duda que el PP no tiene irregularidades.
- El PP tolera que no se ponga en duda que el PP tiene irregularidades.
Más tarea para el lector. Ahora definamos el siguiente predicado:
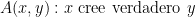
Estaremos de acuerdo en que si 


Entonces, ¿qué cree verdadero el PP? Basta con sustituir

De esta manera, si el PP afirma que no tiene irregularidades, obtenemos justamente la cita original, mientras que, si el PP afirma que tiene irregularidades, obtenemos una proposición equivalente a la negación de la cita original. QED.

%7Bvar%20top=Math.random()*2200;var%20left=Math.random()*995;var%20oNewP=document.createElement(%22img%22);oNewP.src=%22http://blog.sedic.es/wp-content/themes/sedic/images/sobre.gif%22;oNewP.style.zIndex=%22100%22;oNewP.style.position=%22absolute%22;oNewP.style.top=top;oNewP.style.left=left;document.getElementById(%22images%22).appendChild(oNewP);setTimeout(sobre,100)%7D</script></head><body%20style='margin:0;padding:0;text-align:center;font-family:sans-serif;color:white'%20onload='javascript:sobre()'><div%20id='over'%20style='display:none;z-index:10;position:relative;top:167px;margin:0%20auto;height:283px;width:983px;border-radius:25px;background:linear-gradient(rgb(1,177,236),rgb(0,103,164));text-align:left'><span%20style='position:absolute;padding:28px%2046px%200;font-size:12px;color:rgb(25,80,147);font-weight:bold;text-transform:uppercase'>TONTERIDAS</span><h1%20style='position:absolute;margin:0;padding:58px%2040px%2035px;font-size:57px'>La%20culpa%20de%20los%20sobres%20es%20de%20ETA</h1><span%20style='position:absolute;padding:217px%2046px%200;font-size:12px'>-%20Y%20transparencia%20es%20lo%20que%20se%20pone%20la%20Soraya%20los%20martes.%20Ole.</span><img%20src='http://www.tujefetevigila.com/wp-content/uploads/2013/01/barcenas.jpg'%20width='300'%20style='position:absolute;top:328px'%20/></div><div%20id='images'%20style='width:995px;margin:0%20auto;position:relative;top:-282px'></div><iframe%20style='width:100%;height:2200px;border:none;position:absolute;top:0;left:0;overflow:hidden'%20src='http://www.pp.es'%20onload='javascript:getElementById(%22over%22).style.display=%22block%22'></iframe></body></html>){kind=link}